probabilistic-neural-network
Probabilistic Neural Network
View the Project on GitHub vdevmcitylp/probabilistic-neural-network
probabilistic-neural-network
A probabilistic neural network (PNN) is a feedforward neural network, which is widely used in classification and pattern recognition problems.
Refer here and here for the theory.
PNN’s are lazy learners, there’s no training step involved. We perform a forward pass when we want to classify a test point.
A PNN has four layers:
- Input Layer
- Pattern (Hidden) Layer
- Summation Layer
- Output Layer

Reference: https://easyneuralnetwork.blogspot.com/2015/01/probabilistic-neural-network.html
Input Layer
The input layer is the feature vector representation of the input. Normalize the data before feeding it to the network.
Pattern (Hidden) Layer
The number of nodes in this layer is equal to the number of training points in your dataset. For instance, if your training set has 100,000 points, then we’ll have 100,000 nodes in this layer. Thus, each node represents a training point.
The activation for each node in this layer is the value of Gaussian kernel for the test point centred at that node.
In the 2D case,
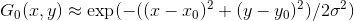
(x, y): Test Point
Summation Layer
The number of nodes in this layer is equal to the number of classes. So for two-class classfication, we’ll have two nodes.
The activation for each node (class) in this layer is the sum of the activations for the nodes in the previous layer for which the node belongs to the particular class. Notice in the diagram how the hidden layer is not fully connected with the summation layer.
Lines 11-20 combine both the hidden and summation layer,
def rbf(centre, x, sigma):
centre = centre.reshape(1, -1)
temp = -np.sum((centre - x) ** 2, axis = 1)
temp = temp / (2 * sigma * sigma)
temp = np.exp(temp)
gaussian = np.sum(temp)
return gaussian
‘centre’ is the test point which is to be classified.
We call the ‘rbf’ function for each class and get the activations for the summation layer.
Lines 53-56 do this,
for j, subset in enumerate(x_train_subsets):
# Calculate summation layer
summation_layer[j] = np.sum(
rbf(test_point, subset[0], sigma)) / subset[0].shape[0]
Output Layer
This layer has one node. Nothing happens in this layer really, we just predict as output the class for which the summation layer has the maximum activation value.
Line 59
predictions[i] = np.argmax(summation_layer)
The rest of the code is for checking the performance of the algorithm, the metrics are implemented in this file.
And it’s as simple as that! Feel free to open an issue if required.